alertmanager 的上层封装
Prometheus 部署之后很少会改动,尤其是做了服务发现,就不需要频繁新增 target。但报警的配置是 很频繁的,如修改阈值、修改报警人等。alertmanager 拥有丰富的报警能力如分组、抑制等,但如果你 要想把他给业务部门使用,就要做一层封装了,也就是报警配置台。用户喜欢表单操作,而非晦涩的 yaml,同时他们也并不愿意去理解 promql。而且大多数公司内已经有现成的监控平台,也只有一份短 信或邮件网关,所以最好能使用 webhook 直接集成。
例如: 机器磁盘使用量超过 90% 就报警,rule 应该写为: disk_used/disk_total > 0.9
如果不加 label 筛选,这条报警会对所有机器生效,但如果你想去掉其中几台机器,就得在disk_used和 disk_total后面加上{instance != “”}。这些操作在 promql 中是很简单的,但是如果放在表单里操作,就 得和内部的 cmdb 做联动筛选了。
对于一些简单的需求,我们使用了 Grafana 的报警能力,所见即所得,直接在图表下面配置告警即 可,报警阈值和状态很清晰。不过 Grafana 的报警能力很弱,只是实验功能,可以作为调试使用。
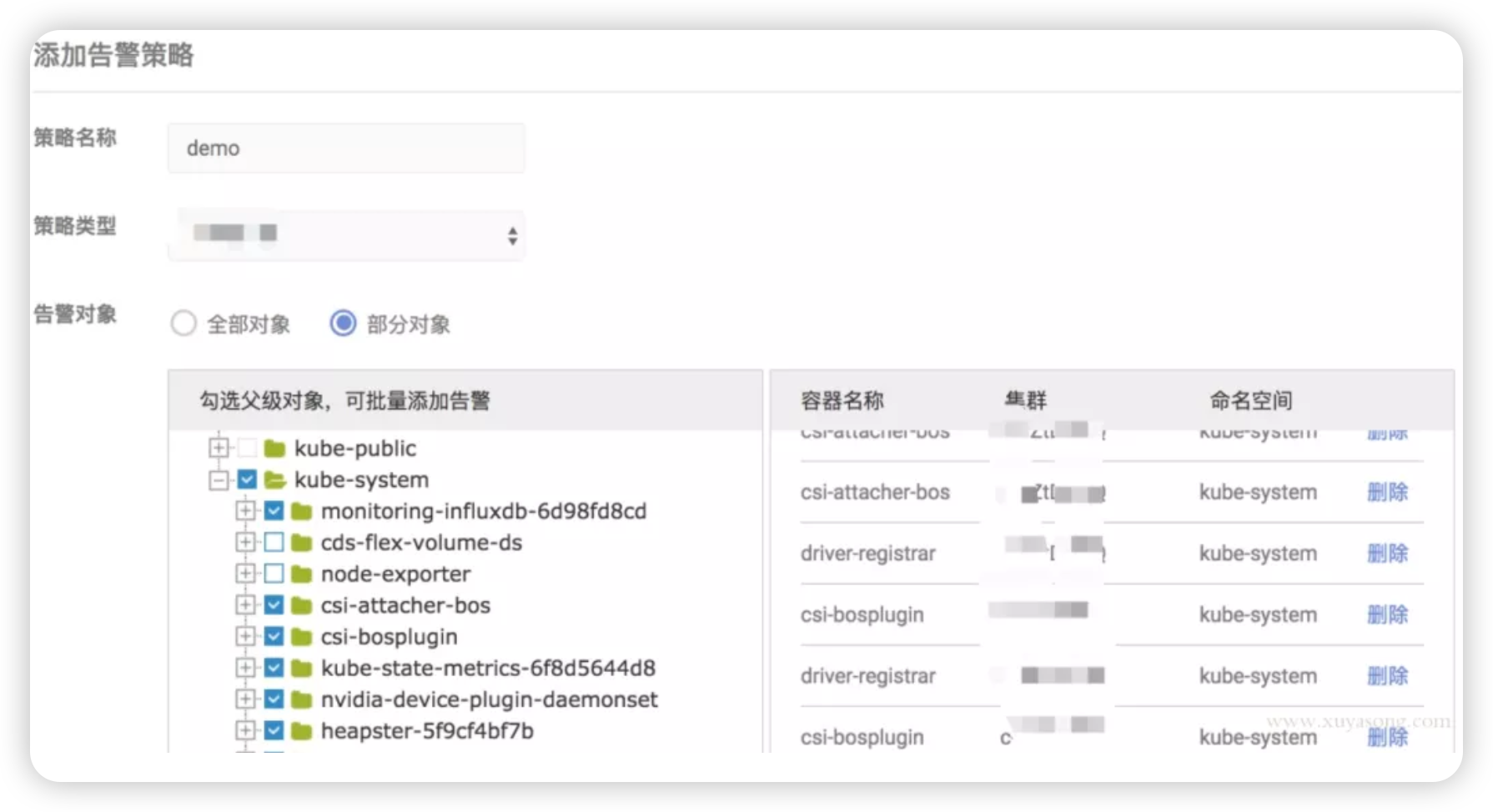
对于常见的 pod 或应用监控,我们做了一些表单化,如下图所示:提取了 CPU、内存、磁盘 IO 等 常见的指标作为选择项,方便配置。
使用 webhook 扩展报警能力,改造 alertmanager, 在 send message 时做加密和认证,对接内 部已有报警能力,并联动用户体系,做限流和权限控制。
调用 alertmanager api 查询报警事件,进行展示和统计。
对于用户来说,封装 alertmanager yaml 会变的易用,但也会限制其能力,在增加报警配置时,研发和 运维需要有一定的配合。如新写了一份自定义的 exporter,要将需要的指标供用户选择,并调整好展示 和报警用的 promql。还有报警模板、原�生 promql 暴露、用户分组等,需要视用户需求做权衡。